
快速入门 NeurAI#
作者: Joyee Wang
本文主要讲解 NeurAI 框架的特点。

以下是 NeurAI 框架的主要特点:
基于 JAX : NeurAI 框架建立在 JAX 库之上,充分利用了 JAX 高性能计算和自动微分的能力。即时编译使 JAX 能够利用现代硬件的计算能力来加速计算,借助 JAX 的张量并行计算及自动微分支持,NeurAI能够为用户提供丰富的神经元模型、突触模型和学习机制,以促进神经科学实验和研究。
支持分布式训练:NeurAI提供了强大的分布式训练支持,让用户能够充分利用现有的数据并行和模型并行方法。NeurAI的分布式工具能够有效地解决分布式训练中的各种挑战和难题,如数据同步、通信开销、节点调度及容灾等。无论是小规模的本地集群还是大规模的云端集群,NeurAI都能够提供高效稳定的训练性能,为用户的深度学习任务提供强有力的支持和保障。
支持脉冲神经网络:脉冲神经网络是仿真大脑中神经元之间电信号传输的人工神经网络, NeurAI 提供了一系列 脉冲神经网络 模型,如 SNNLIF、SNNSRM、Slayer、Exodus 、SRNN 等,以支持脉冲神经网络的仿真模拟。并提供了替代梯度和损失函数,支持网络的梯度训练和反向传播。这些强大的工具使开发人员能够轻松构建、训练和评估 脉冲神经网络 模型。
支持大规模脑仿真:NeurAI包含针对大规模脑仿真的各种工具,用户可以利用GPU、类脑芯片等加速硬件资源进行大规模脑仿真实验。同时,NeurAI还提供了灵活的接口和扩展机制,使用户能够轻松地集成自定义脑模型和算法。通过这些支持措施,用户可以在大规模脑仿真研究中获得更高的性能和更丰富的功能。
支持混合神经网络训练:NeurAI提供了通用的面向对象编程范式,用户可以在一个网络模型中灵活地结合不同类型的神经网络结构和学习方法。通过通用的编程接口,用户可以轻松地定义和组合各种类型的神经网络层、损失函数和优化器,实现混合神经网络模型的训练。这种灵活的编程范式使用户能够针对特定任务和数据特征选择最适合的网络结构和学习方法,从而提升模型的性能和泛化能力。
支持类脑芯片部署:NeurAI 提供了针对类脑芯片的计算图转换工具,用户可以利用这一工具将各种类型的神经网络模型高效地部署至类脑芯片平台。这个转换工具具有高度的灵活性,能够自动优化和适配不同类型的模型结构,确保其在类脑芯片上的高效执行和性能表现。通过NeurAI转换工具,用户无需深入了解类脑芯片的底层架构和编程细节,即可轻松地将其训练好的神经网络模型部署到类脑芯片上,并实现实时的推理和计算任务。这种便捷而高效的部署方式极大地降低了用户的开发和部署成本。目前NeurAI支持 KA200类脑芯片。
NeurAI 中的模型构建#
本文从模型构建的整个工作流入手,介绍 NeurAI 的基本概念和使用方法。NeurAI 集成了 JAX 的核心功能,支持用户使用即时编译( JIT )的方式运行模型。 整个 NeurAI 的工作流采用惰性执行的思路,在模型实际运行时, 系统会捕获其静态图并编译为针对目标设备优化的高效代码。 编译后的代码会被缓存,随后的函数调用会重用缓存的代码。
相比于 JAX 原始的函数式编程, NeurAI 向用户提供了更通用的面向对象编程( OOP )范式, 无论是 深度学习 、脉冲神经网络,还是 脑仿真,都可以在这一套架构下进行构建、训练及部署。
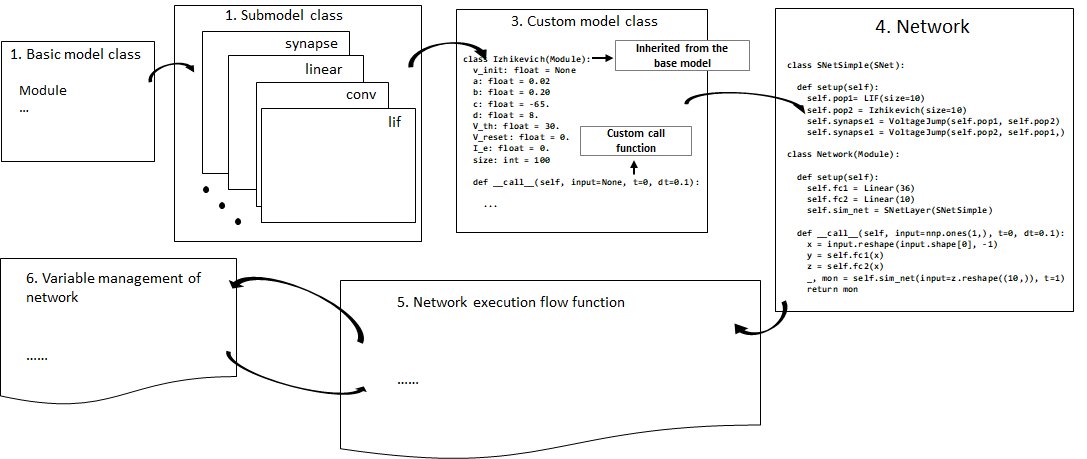
我们从谷歌 Flax 库最初的设计原则中汲取灵感,并通过融入类脑计算元素丰富了原始架构。
一般来说,neurai.nn 模块下的模型都继承自 neurai.nn.module.Module 类,
这个类是使用 dataclasses 数据类构造的,允许用户利用 neurai.nn.module.Module.setup 函数进行对象初始化。
NeurAI 自动将这些对象转换为纯函数,从而确保与其他 JAX 功能的兼容性。
需要注意 neurai.nn.module.Module 中的两个函数: neurai.nn.module.Module.init 和 neurai.nn.module.Module.run 。
neurai.nn.module.Module.init 用于初始化模型参数, neurai.nn.module.Module.run 用于运行模型。
neurai.nn.module.Module.run 函数中,会根据模型结构去动态创建一个 纯函数 ,以保证模型对象能够被 JIT 编译。
这个创建纯函数的过程主要包括抽取原模型中 __call__ 函数并与模型解绑、克隆模型对象、获取模型参数信息、根据模型变量结构生成变量字典等。
变量字典#
在构建变量字典时, NeurAI 将模型中的变量分成了 variable , param 和 frozen_param 三种类型,
以适应 JIT 条件下的不同模型应用场景。
variable 类型的变量是不可训练变量,即不参与反向过程,但在前向过程中会有值的改变,这种改变属于典型的 inplace 操作。
这种变量的应用场景一般出现在 脑仿真 模型中, 如:神经元的膜电压(membrane voltage)、电流(synaptic currents)等,以下为神经元更新函数中的一段代码:
def __call__(self, input=None, t=0):
self.input_spike = self.variable('input_spike', zero_func, self.size, float, mutable=True)
self.v = self.variable('v', ones_func, self.size, float, lambda x: x * self.v_init, mutable=True)
self.I_syn = self.variable('I_syn', zero_func, self.size, float, mutable=True)
上述代码中, input_spike 表示输入的脉冲, v 表示神经元的膜电压, I_syn 表示突触电流。
param 类型的变量用于训练,前向过程中保持不变,但在反向过程中会根据梯度值进行更新,在 NeurAI 支持的 neurai.grads.autograd.BP 、 neurai.grads.autograd.BiPC 、 neurai.grads.autograd.EP 、 neurai.grads.autograd.PC 等学习方法中会被用到。
frozen_param 类型的变量将与 param 一起参与训练过程,但不参与更新。
使用 neurai.nn.module.Module.variable 自定义变量,用户需要设置 mutable 和 frozen_params 两个参数,在模型初次 neurai.nn.module.Module.run 的过程中,
系统会根据这两个参数信息确定变量的实际类型,并生成变量字典。
以下是一个冻结weight的 neurai.nn.layer.linear.Linear 层的示例代码:
class Linear(Module):
features: int
bias: bool = True
param_dtype: Any = jnp.float32
w_initializer: Callable = KaimingUniformIniter()
b_initializer: Optional[Callable] = UniformIniter(-0.08, 0.08)
frozen_params: dict = {"weight": True}
def __call__(self, input) -> jnp.ndarray:
self.W = self.variable('weight', self.w_initializer, (input.shape[-1], self.features), self.param_dtype, mutable=True, is_frozen=self.get_frozen_value("weight"))
y = input @ self.W
if self.bias:
bias = self.variable('bias', self.b_initializer, (self.features,), self.param_dtype, mutable=True, is_frozen=self.get_frozen_value("bias"))
y += jnp.reshape(bias, (1,) * (y.ndim - 1) + (-1,))
return y
目前的变量分类方法,主要是为了解决函数作用域之外的可变值会导致 JIT 失效的问题。 未来可能会有更好的解决方案。
Note
关于参数冻结相关的示例,可以看这篇: 参数冻结